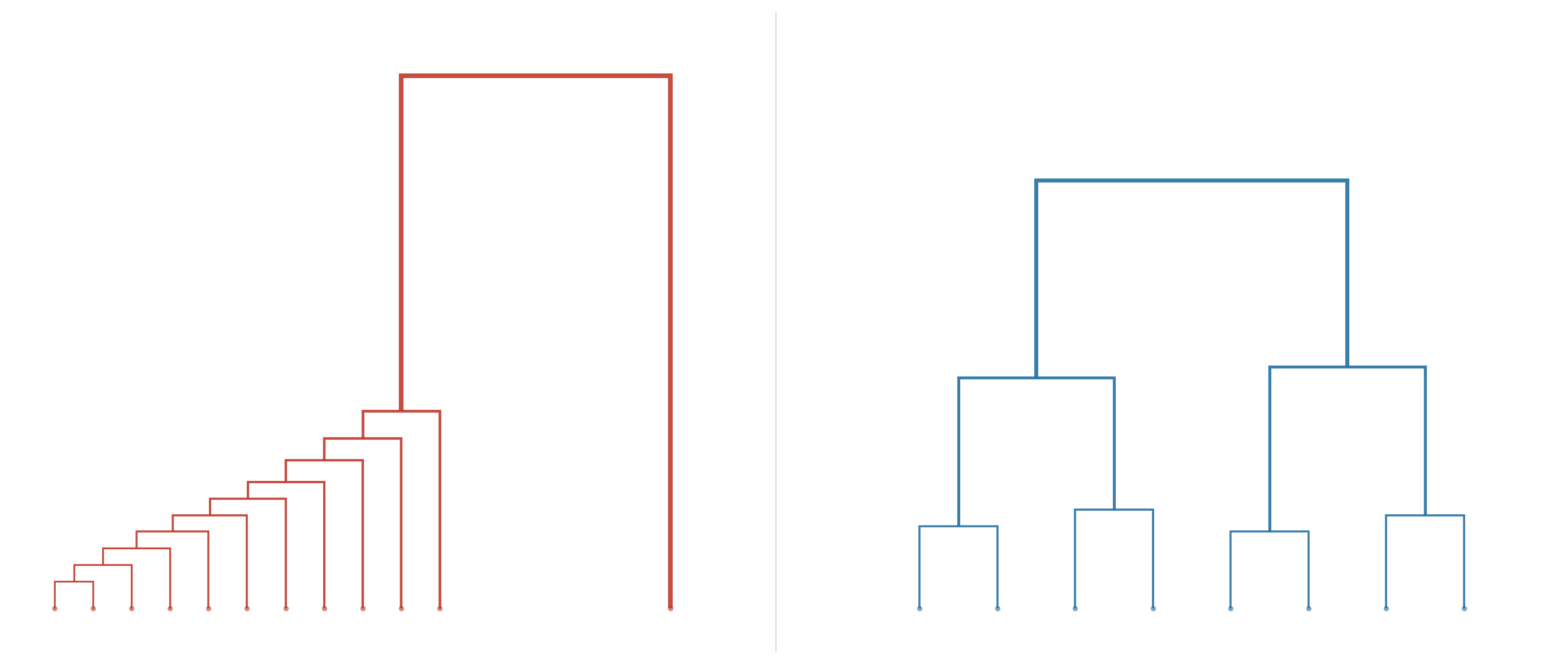
Towards Balanced Dendrograms in Hierarchical Document Clustering
An investigation into unbalanced dendrograms produced by Hierarchical Agglomerative Clustering, and the solutions we found, including a look at the recently proposed Chamfer Linkage.

For the consumer, chatbots are synonymous with AI. The browser serves as a universal workspace for daily work and life, delivering the chatbots we can’t get enough of, but there is a case for deeper integration - embedding AI within the browser experience itself. Should AI be in the browser? If so, how?

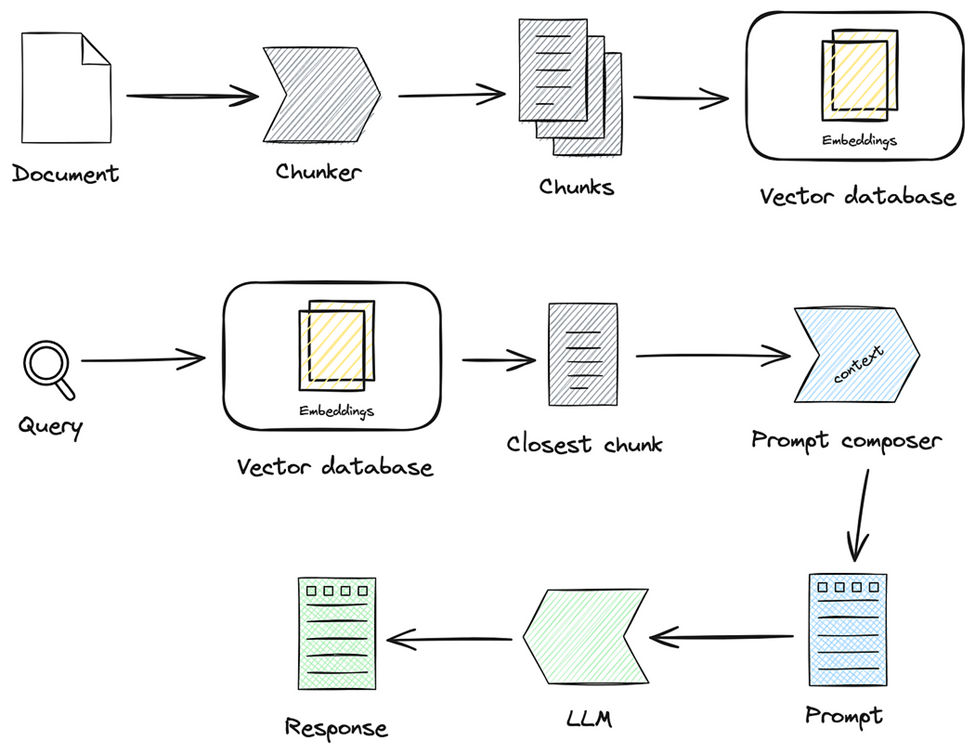
Retrieval-Augmented Generation (RAG) pipelines pair large language models (LLMs) with an external retrieval component. By fetching domain‐relevant chunks of text, these systems can provide more up-to-date or domain-specific answers than models relying solely on static training. Yet, they also add complexities: the system depends on both retrieval quality and generation fidelity.

Hashtags were a defining innovation of Web 2.0; what started as a user-invented hack on Twitter in 2007 has become entrenched as an organizing tool in platforms like Instagram and TikTok, driving community curation and content discovery. This was “folksonomy” in action: bottom-up labeling that adapts faster than top-down taxonomies ever could. But with #AI, can we reinvent the concept of taxonomy to combine the “evolveability” of a bottom-up approach with the “systemizability” of a top-down approach? That is the promise of topic modeling.


Retrieval-Augmented Generation (RAG) pipelines have revolutionised how we integrate custom data with large language models (LLMs), unlocking new possibilities in AI applications. However, evaluating the effectiveness of these pipelines has presented a major challenge for most real-world applications. In this post, we’ll look deeper into the pain points of RAG pipeline evaluation and explore strategies to overcome them.



This site will focus on all aspects of agentic-RAG motivated by the pursuit to create an effective AI co-pilot for research tasks. Please subscribe to be notified when new content is added. Thanks!