Towards Balanced Dendrograms in Hierarchical Document Clustering
Background
Given a large corpus of documents, we can create a hierarchical organisation such that the topical relatedness of each document is organised into a tree, or a dendrogram. When trying to construct such a dendrogram to be used as a topic routing decision tree, we encountered a problem.
Despite working with relatively large datasets (3000+ articles), our dendrograms typically produced highly unbalanced decision trees. In this article, we’ll cover our investigation into this issue and the solution we implemented. We also discuss some recent research ideas relevant to the problem.
The Problem: Unbalanced Dendrograms
When clustering a number of highly varying noisy items (such as article text embeddings) using HAC, we typically expect clusters to be globular — i.e. not exhibiting unique shapes such as rings or lines. We might also expect, if the corpus’s spread of concepts is even enough, for most clusters to be of similar size.
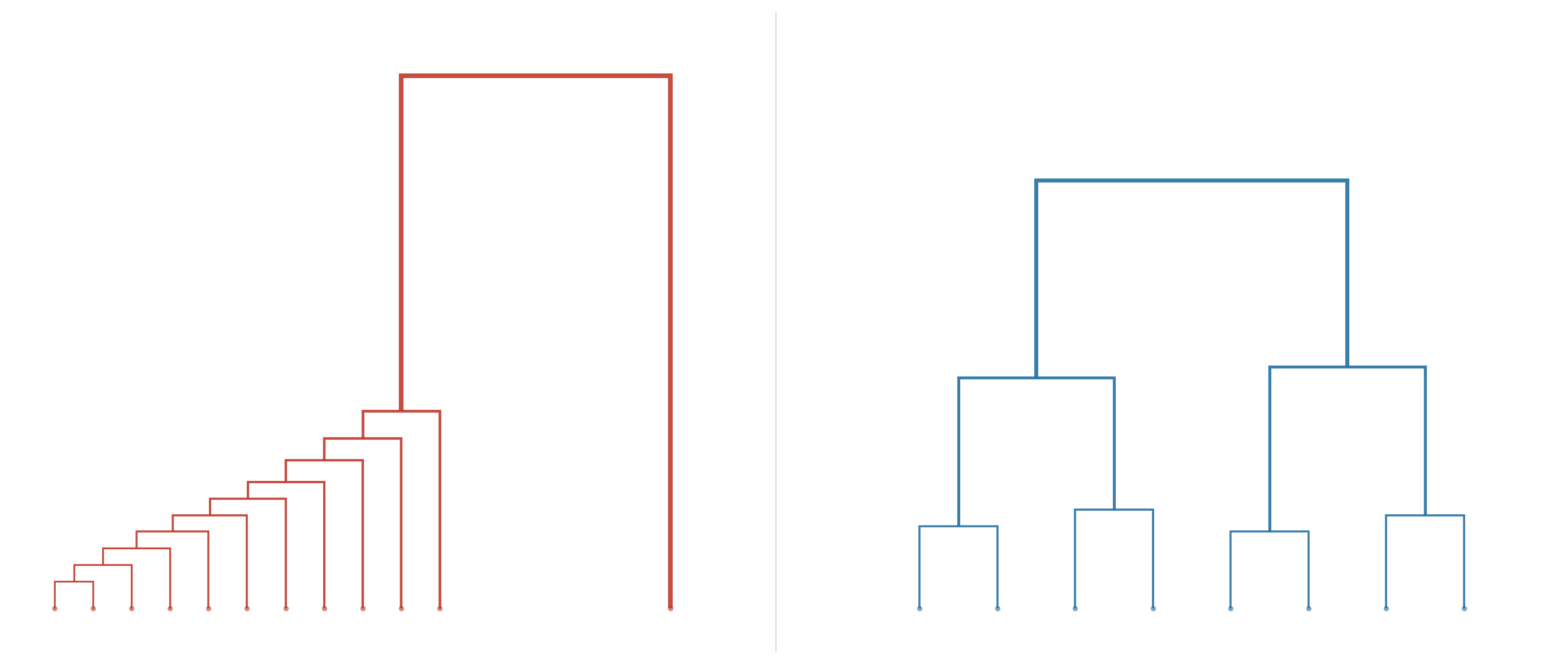
A natural requirement is for the resulting dendrogram to be balanced. This mitigates the risk of the dendrogram taking on a degenerate tree structure, such as when only one article is connected to the root (Figure 1).
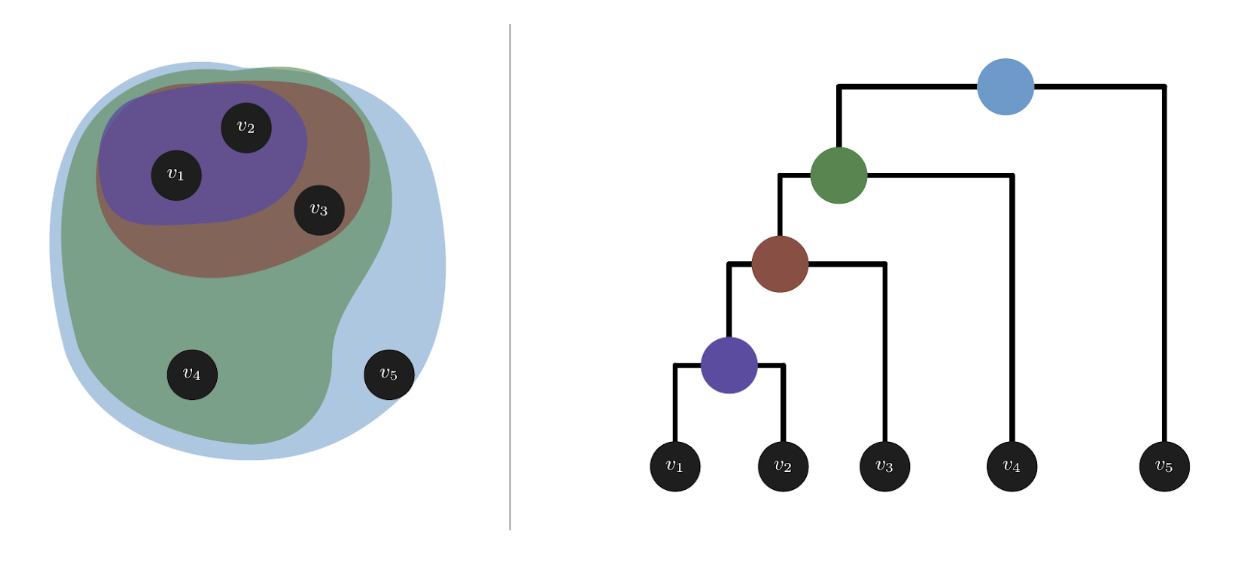
Figure 1. Unbalanced Dendrogram
We want a roughly balanced dendrogram, with each cluster representing the “concepts” or “super-concepts” of its children (Figure 2). This is especially important when splitting a collection of articles into Mutually Exclusive and Collectively Exhaustive (MECE) sets — for example, deriving n categories for a given set of scholarly readings.
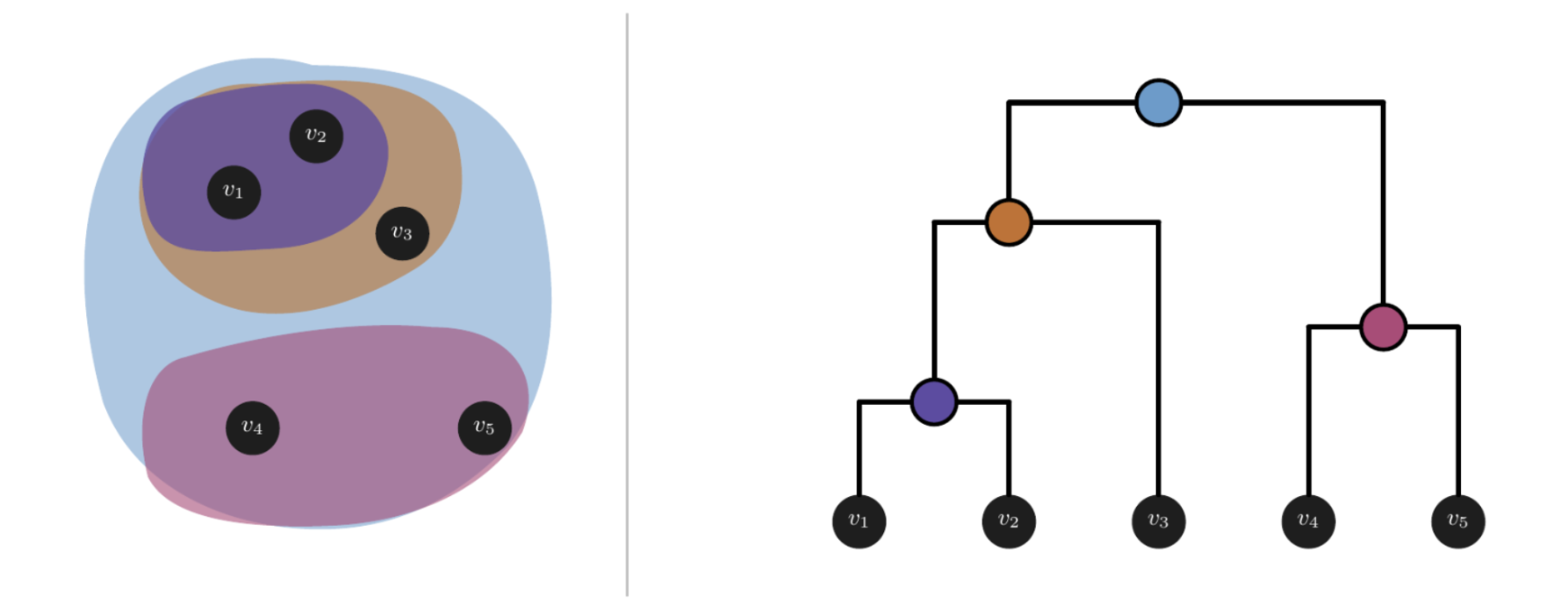
Figure 2. Balanced Dendrogram
Before describing our approach, it is worth reviewing the common linkage methods used in HAC:
- Single Linkage — the minimum distance between any pair of points from each cluster.
- Complete Linkage — the maximum distance between any pair of points across each cluster.
- Centroid Linkage — the distance between the cluster centroids.
- Ward Linkage — the increase in within-cluster variance after merging.
All of these can be implemented in O(n²) or O(n² log n) time. The distance function itself can vary; common choices include Euclidean, Manhattan, and Cosine Similarity.
Our Investigation
1 Single Linkage with Cosine Similarity
We first attempted Single Linkage with Cosine Similarity, merging the two clusters with the highest cosine similarity between any two points across each cluster. However, Single Linkage has a known tendency to produce non-globular patterns and is sensitive to outliers.
In our experiments, Single Linkage produced highly unbalanced dendrograms (similar to Figure 1), despite no obvious cause upon closer inspection of the data.
2 Ward Linkage
We then switched to Ward Linkage (which uses Euclidean distance). Ward Linkage measures the increase in within-cluster variance after merging clusters A and B, repeating for every pair-wise combination of clusters, and finally merging the pair with the minimum increase in within-cluster variance.
We found that Ward Linkage drastically reduced the number of catastrophic outliers in our dendrograms and generally produced far more evenly-sized clusters across our dataset.
Recent Research: Chamfer Linkage
Researching even better approaches, we came across a recent paper by Gowda et al. (2026), published 11 February 2026. This paper is motivated by much of the same concerns we cover here — namely the need for balanced dendrograms and accurate conceptual representation.
The paper introduces a novel linkage function called Chamfer Linkage, taking inspiration from the Chamfer Distance used in computer vision. It is defined as the sum of distances from all points in one cluster to the corresponding closest points in the other cluster.
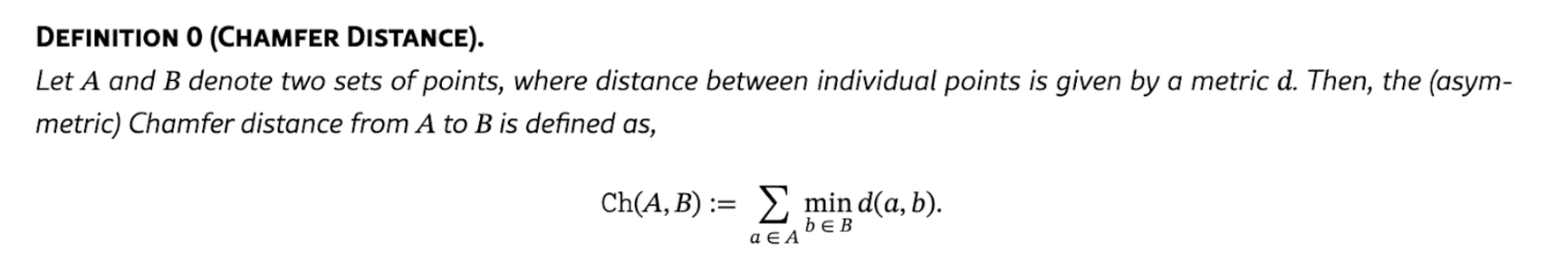
Figure 3. Chamfer Distance definition from Gowda et al. (2026)
Although we have not yet applied Chamfer Linkage in our own work, the paper’s tests suggest it outperforms all other common linkage methods on average in terms of:
- Adjusted Rand Index (ARI)
- Normalized Mutual Information (NMI)
Notably, Chamfer Linkage can be implemented in the same asymptotic time complexity, O(n²), as other linkage functions.
Summary
| Linkage Method | Distance Function | Balanced? | Notes |
|---|---|---|---|
| Single | Cosine Similarity | ✗ | Prone to chaining; sensitive to outliers |
| Ward | Euclidean | ✓ | Our current approach; works well in practice |
| Chamfer | Flexible | ✓ (reported) | Promising; outperforms others in ARI/NMI per Gowda et al. 2026 |
Our recommendation for practitioners dealing with imbalanced dendrograms on noisy text embedding corpora is to start with Ward Linkage as a robust baseline, and consider exploring Chamfer Linkage as the research matures.
References
- Gowda, K. N., Fletcher, W., Bateni, M., Dhulipala, L., Hershkowitz, D. E., Jayaram, R., & Łącki, J. (2026). Chamfer-linkage for hierarchical agglomerative clustering. arXiv.
- Murtagh, F., & Contreras, P. (2012). Algorithms for hierarchical clustering: an overview. Wiley Interdisciplinary Reviews: Data Mining and Knowledge Discovery, 2(1), 86–97.